Как в в DAX для Power BI использовать Time Intelligence год до даты, квартал до даты, месяц до даты?
Анализ времени (Time Intelligence) является важной частью многих BI-решений. В этой статье мы сперва объясним, что такое анализ времени и каковы требования для настройки вычислений учета времени, а затем расскажу о функциях и выражениях DAX, которые помогают получить представление, такое как сравнение по годам, сравнение по годам и т. д.
Необходимое условие
Для запуска примеров из этой статьи вам понадобится набор данных AdventureWorksDW. и таблица, которую мы используем, - это только одна таблица: FactInternetSales для загрузки в Power BI.
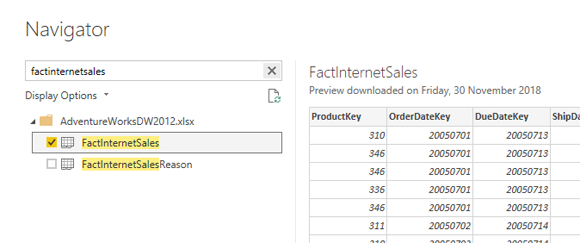
Что такое Time Intelligence?
Функции Time Intelligence в DAX представляют собой набор функций, которые дают вам представление о измерениях даты и времени. Большая часть анализа по дате и времени относится к этой категории, например; год к дате, квартал к дате, месяц к дате, расчеты за тот же период прошлого года и т. д. Все эти расчеты имеют одно общее измерение: измерение даты/времени.
Перед использованием функций DAX
Прежде чем использовать какую-либо функцию DAX, обеспечивающую вывод времени, вы должны знать, что для работы всех этих функций существует требование. Если вы хотите работать с этими функциями, вы должны иметь измерение даты (некоторые люди называют это календарным или измерением времени, хотя измерение времени отличается) в вашей модели данных. Это измерение даты должно иметь некоторые требования:
Измерение даты, приемлемое для функций анализа времени DAX, должно:
- иметь одну запись в день;
- начинаться с минимальной даты в поле даты или раньше и заканчиваться максимальной датой в поле даты или позже.
- не пропускать ни одной даты (если нет продаж на 1 января, эта дата все же должна быть в этой таблице. Это одна из причин, по которой вам нужна отдельная таблица дат)
Откуда получить измерение даты?
Есть два варианта, когда вы хотите использовать измерение даты. Используйте пользовательское измерение даты или встроенное измерение по умолчанию. Мы подробно рассматривали разницу между этими двумя типами измерения и плюсы и минусы каждого. Если вы хотите использовать измерение даты по умолчанию, никаких дополнительных шагов не требуется.
В этой статье мы будем использовать измерение даты по умолчанию в Power BI, поэтому дополнительная таблица не требуется. Измерение даты по умолчанию будет автоматически создано для каждого поля даты в вашей модели данных. Мы объяснили это подробнее здесь.
Год до даты: TotalYTD
Давайте начнем пример с простой функции для вычисления года до даты. Расчет года до даты - это совокупность значений с начала года до указанной даты. Например, значение продаж в годовом исчислении может быть суммой всех продаж с 1 января этого года до указанной даты. Специально для DAX существует функция DAX, которая называется TotalYTD. Вот функция TotalYTD:
TotalYTD( <expression>, <dates>, [<filter>], [<year end date>])

Первые два параметра являются обязательными:
- Expression: выражение, которое применяет агрегацию значения
- dates: поле даты измерения даты.
В нашем примере мы вычисляем сумму поля SalesAmount в FactInternetSales. Таким образом, выражение будет следующим: Sum(FactInternetSales[SalesAmount]).
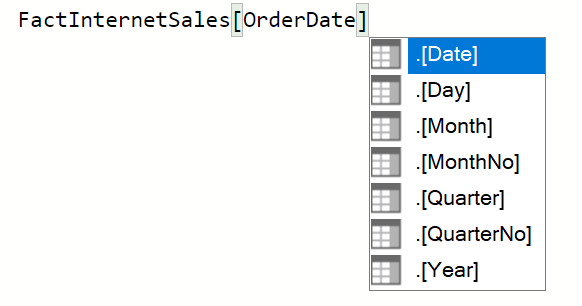
Для поля даты, так как мы используем измерение даты по умолчанию; при вводе имени поля даты (в данном случае OrderDate из FactInternetSales) у вас будет возможность выбрать поле из этой таблицы (помните, что поле даты является таблицей дат позади сцены, Power BI создает измерение даты по умолчанию для каждое поле даты) выберите поле .[Date]. Это подразумевает поле даты в таблице дат по умолчанию.
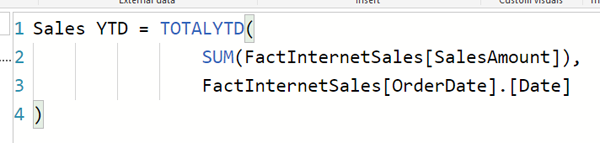
Таким образом, в результате вот выражение для расчета “год до даты”: (Обратите внимание, что это показатель, а не столбец)
|
1 2 3 4 |
Sales YTD = TOTALYTD( SUM(FactInternetSales[SalesAmount]), FactInternetSales[OrderDate].[Date] ) |
и пример вывода будет следующим:
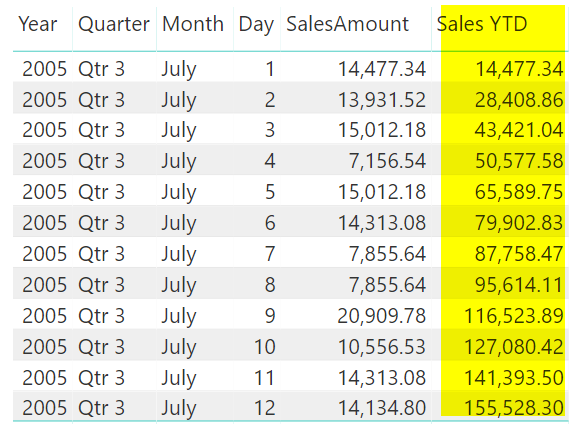
Как вы можете видеть, показатель Sales YTD представляет собой накопленные значения всех дат до начала года (для получения правильного результата вы должны иметь OrderDate в визуале, и его следует упорядочить по возрастанию OrderDate). На приведенном выше рисунке показан расчет по каждому дню, если мы удалим день из визуального элемента (вы можете удалить его из раздела «Fields» визуального элемента),
затем вы можете рассчитать год до даты на месячном уровне, как показано ниже:
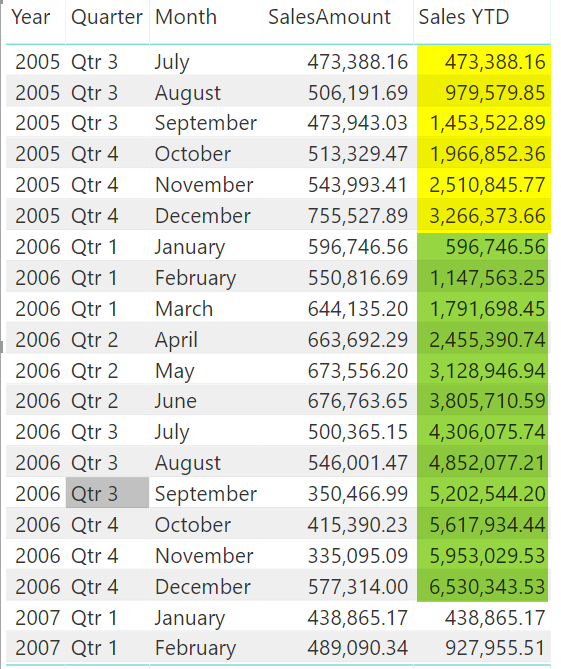
Как вы можете видеть на скриншоте выше, расчет “год до даты” за каждый месяц - это совокупный объем продаж за все месяцы до этого (с января того года).
Год до даты. Другой подход: DatesYTD
TotalYTD является одним из методов расчета годовой стоимости. Есть другой способ, который может быть полезен в более сложных выражениях DAX, когда вы хотите объединить несколько критериев фильтрации вместе. Таким образом, используется функция DatesYTD в сочетании с функцией Calculate. DatesYTD - это функция, которая принимает только два параметра, один из которых является необязательным;
DatesYTD(<dates>, <year end date>)
DatesYTD возвращает таблицу в качестве вывода; таблица со всеми датами в периоде от года до даты. Вот почему для расчета агрегации в этом диапазоне дат необходимо использовать такую функцию, как Calculate.
Вот как работает расчет с функцией DatesYTD;
|
1 2 3 4 5 6 |
Sales YTD Method 2 = CALCULATE( SUM(FactInternetSales[SalesAmount]), DATESYTD( FactInternetSales[OrderDate].[Date] ) ) |
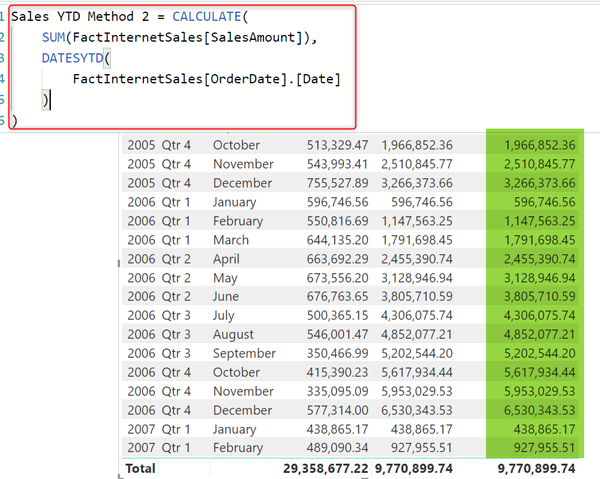
Вы можете спросить, какой из них является предпочтительным вариантом? TotalYTD или DatesYTD. Ответ зависит от типа фильтра, который вы используете. Если вы используете несколько критериев фильтра, то мы бы посоветовали, DatesYTD, потому что, когда он используется внутри Calculate, вы можете применить любой фильтр, который вы хотите. Возможно, вы сможете сделать это еще с TotalYTD, но вы, вероятно, усложните выражение.
Фискальный или финансовый год до даты
Рассчитать календарный год до даты было легко, как насчет фискального или финансового расчета? у нас есть функция для них? Нет. Однако есть параметр, который можно добавить в выражение и который делает расчет фискальным. Параметр <year end date> является необязательным параметром, который мы не использовали в предыдущем примере. Если вы не назначите значение для этого параметра, будет использоваться значение по умолчанию, равное 31 декабря каждого года. Если вы хотите указать значение для этого параметра, вот пример того, как вы можете это сделать:
|
2 3 4 5 |
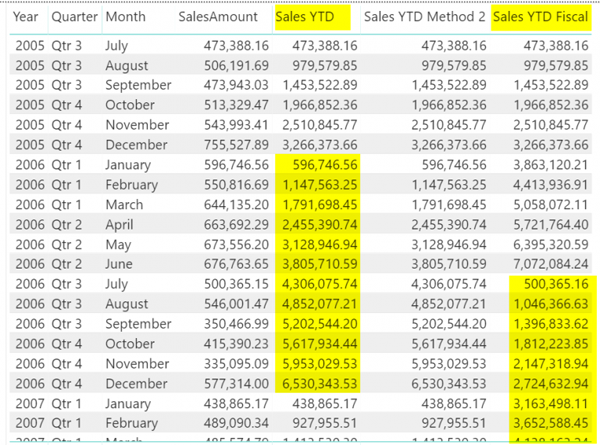
Sales YTD Fiscal = TOTALYTD( SUM(FactInternetSales[SalesAmount]), FactInternetSales[OrderDate].[Date], "06/30" ) |
Как вы можете видеть по структуре, которую мы предоставили, дата окончания года была месяц/день. Есть также несколько других опций, которые вы можете использовать, например, 06-30, 6/30, 30 июня или 30 июня. Все, что разрешает сценарий месяц/день.Ррекомендуется использовать формат месяца/дня. Значение «06/30» в качестве параметра означает, что конец финансового года наступает 30 июня каждого года, а результатом будет 1 июля года. Вот выходные данные, поскольку вы можете видеть, что расчет перезапускается в июле каждого года вместо календарного года до даты, которая начинается с января.
Подход очень похож, если вы хотите использовать подход DatesYTD, вот код:
|
3 4 5 6 7 |
Sales YTD Fiscal Method 2 = CALCULATE( SUM(FactInternetSales[SalesAmount]), DATESYTD( FactInternetSales[OrderDate].[Date], "06/30" ) ) |
Расчет за квартал до даты: TotalQTD
Когда вы знаете, как работает расчет года до даты, вы можете догадаться, как он будет работать и за квартал. Единственная разница заключается в том, что функция за квартал на сегодняшний день называется TotalQTD. Его можно использовать точно так же, как мы использовали TotalYTD в предыдущем примере;
|
1 2 3 4 |
Sales QTD = TOTALQTD( SUM(FactInternetSales[SalesAmount]), FactInternetSales[OrderDate].[Date] ) |
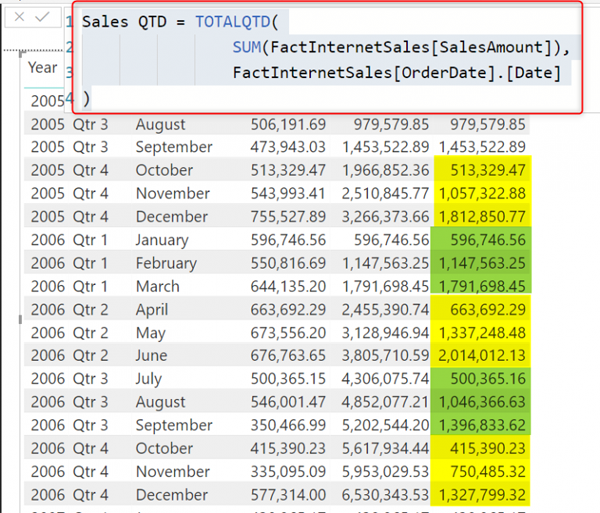
Как видите, в этом расчете накапливаются значения продаж до конца каждого квартала.
Расчет за квартал до даты: DatesQTD
Подобно DatesYTD, есть также функция для DatesQTD, которую можно использовать точно так же. Вот код для нее:
|
1 2 3 4 5 6 |
Sales QTD Method 2 = CALCULATE( SUM(FactInternetSales[SalesAmount]), DATESQTD( FactInternetSales[OrderDate].[Date] ) ) |
Расчет месяца до даты: TotalMTD
Чтобы рассчитать месяц до даты, вы можете использовать функцию TotalMTD, очень похожую на другие функции, которые вы видели в предыдущих примерах. Вот ее код:
|
1 2 3 4 |
Sales MTD = TOTALMTD( SUM(FactInternetSales[SalesAmount]), FactInternetSales[OrderDate].[Date] ) |
И вывод (обратите внимание, что вы можете проверить его лучше, когда у вас есть ДЕНЬ на визуальном элементе, чтобы увидеть, как происходит накопление);
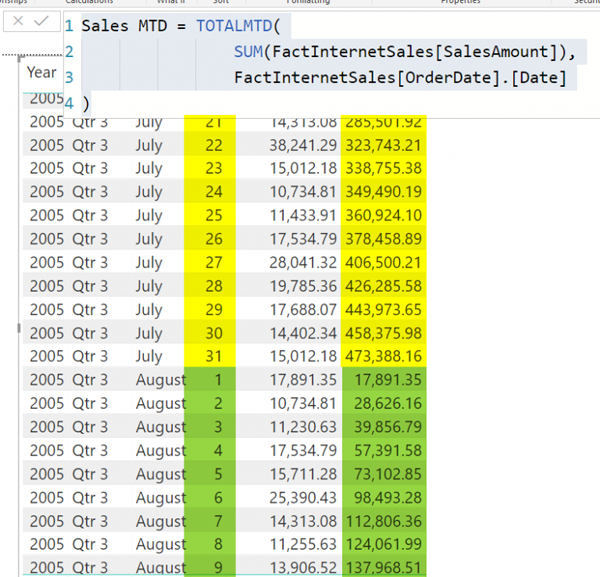
Расчет месяца до даты: DatesMTD
Тот же самый подход может быть применен для DatesMTD, как показано ниже:
|
2 3 4 5 6 |
Sales MTD Method 2 = CALCULATE( SUM(FactInternetSales[SalesAmount]), DATESMTD( FactInternetSales[OrderDate].[Date] ) ) |
Больше функций?
Итак, как вы видели в этой статье, не сложно начать использование функций Time Intelligence. В одной из следующих статей мы объясним несколько других функций Time Intelligence.
Источник: http://spbdev.biz/blog/osnovy-time-intelligence-v-dax-dlya-power-bi-god-...
Как скачать ПДФ файлы с гугл диска с запретом на скачивание, после изменения политики безопасности хрома?
Перестал работать скрипт из статьи Как скачать защищенный пдф файл с гугл диска выдает следующую ошибку
jspdf.src = 'https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js'; VM33005:23 This document requires 'TrustedScriptURL' assignment. (anonymous) @ VM33005:23 VM33005:23 Uncaught TypeError: Failed to set the 'src' property on 'HTMLScriptElement': This document requires 'TrustedScriptURL' assignment. at
Ошибка `This document requires 'TrustedScriptURL' assignment` является новым требованием безопасности в некоторых браузерах, таких как Chrome, который требует, чтобы скрипты, которые загружаются через URL, были помечены как доверенные. Это помогает предотвратить подключение вредоносных скриптов к вашей веб-странице.
Для обхода ее нужно сделать следующее:
Использовать метод 1 из скрипта Google Drive PDF Downloader
Вышеупомянутый метод JS работает для простых файлов PDF, но если вы хотите загрузить большие файлы PDF со сложной ориентацией в качестве HD, то простой код JS может не работать так хорошо, здесь вы можете попробовать этот продвинутый трюк, чтобы сохранить защищенный файл Google Drive PDF.
- Скачайте и распакуйте Zip file.
- Откройте Method_1_Script.js.
-
Скопируйте в буфер обмена JS Code.

- Откройте в Гугл документах защищенный файл
-
Перейдите в Dev Console и вставьте JS Code. (как только нажмете ентер скачается файл
"BytesBin_PDF";)
-
Качается файл PDF_DataFile.

-
скопируйте файл в папку Input, эта папка должны быть в разархивированных документах скрипта из пункта 1 Zip file.

-
Если используете Windows, перейдите в папку “Windows” и дважды щелкните на “GeneratePDF.cmd”, если у вас линукс или мак переходите в папку “Linux” и открываете “GeneratePDF”.

- Пойдет конвертация в пдф.
- Ваш скаченный ПДФ файл будет находится в папке “Output” .
- Ура!
Часть статьи переведена из https://bytesbin.com/download-view-only-pdf-google-drive/
Когда и как Чат ГПТ полностью сможет заместить SEO-продвижение?
Чат глубокой персонализации (ГПТ) и SEO (оптимизация для поисковых систем) — это разные технологии, которые служат разным целям и не могут заменить друг друга полностью.
SEO — это процесс оптимизации веб-страниц, чтобы они лучше видны в поисковых системах и привлекали больше трафика на сайт. В основном SEO-оптимизация направлена на улучшение позиции сайта в результатах поиска. Однако, SEO не сможет полностью заменить чат ГПТ, так как основной его задачей является оптимизация сайта для поисковиков и привлечение трафика, а не общение с посетителями и улучшение пользовательского опыта.
Чат ГПТ, с другой стороны, осуществляет персонализацию пользовательского опыта. Он может общаться с посетителями сайта, отвечать на их вопросы, помогать с выбором товаров, предлагать рекомендации и улучшать продажи. Таким образом, он улучшает качество обслуживания клиентов и позволяет повысить конверсию на сайте.
Таким образом, чат ГПТ и SEO являются разными технологиями, которые имеют свои собственные цели. Однако, эти технологии могут совместно использоваться для улучшения позиции сайта в результатах поиска и улучшения пользовательского опыта на сайте.
Почему перегревается ноутбук?
Почему мой ноутбук перегревается, может это из-за попадания пыли в кулер, как я могу решить эту проблему?
Пыль и грязь внутри ноутбука могут помешать правильному функционированию вентилятора.
Если кулер не может охлаждать компоненты ноутбука, то это может привести к перегреву компонентов, что может привести к сбоям и повреждениям компонентов.
Одним из решений этой проблемы является регулярная чистка кулера и других компонентов внутри ноутбука.
Это можно сделать самостоятельно или обратиться за помощью к специалисту в сервисном центре.
В процессе чистки необходимо следить за тем, чтобы не повредить компоненты и не зацепить провода.
Помните! все действия вы выполняете на свой страх и риск, иногда, лучше довериться профессионалам.
Самостоятельная чистка ноутбука от пыли может значительно продлить срок его эксплуатации. Однако, перед тем как начать процесс, необходимо принять несколько мер предосторожности:
1. Отключите ноутбук от розетки и удалите аккумулятор.
2. Не используйте аэрозольные спреи, такие как очиститель для клавиатуры или стекла, могут повредить компоненты ноутбука.
3. Никогда не используйте воду, чтобы очистить компоненты внутри ноутбука.
После того как вы приняли все необходимые меры предосторожности, можно начинать чистку.
Шаг 1: Инструменты и материалы
Вам понадобятся следующие инструменты и материалы:
1. Щетка с мягким ворсом (например, кисть для овощей)
2. Салфетки или мягкие тряпки
3. Канифольный спирт или изопропиловый спирт
4. Воздушный компрессор или пылесос
Шаг 2: Откройте корпус ноутбука
Перед началом чистки необходимо открыть корпус ноутбука. Для этого нужно открутить несколько винтов, которые удерживают корпус, и затем аккуратно открыть его. Обратите внимание на то, как уложены провода, чтобы не повредить их в процессе чистки.
Шаг 3: Очистите вентилятор и систему охлаждения
Следующим шагом является очистка вентилятора и системы охлаждения. Уберите все пыльные частицы с помощью щетки с мягким ворсом или воздушного компрессора. Вентилятор можно удалить, чтобы убрать пыль с его поверхности и лопастей.
Шаг 4: Очистите остальные компоненты
Уберите пыль с других компонентов ноутбука с помощью воздушного компрессора или пылесоса. Обратите внимание, чтобы не повредить клавиши на клавиатуре и другие устройства введения.
Шаг 5: Закройте корпус ноутбука
После того, как вы уберете всю пыль изнутри ноутбука, закройте корпус ноутбука и затяните винты.
Шаг 6: Проверьте работу ноутбука
Включите ноутбук и проверьте, как работает система охлаждения. Если вентиляторы работают более тихо, это означает, что вы успешно убрали пыль из вентилятора. Если они все еще громко работают, возможно, что вы не убрали всю пыль или что вентиляторы нуждаются в замене.
Помните! все действия вы выполняете на свой страх и риск, иногда, лучше довериться профессионалам.
Как установить виндовс на компьютер?
Подскажите как установить виндовс на компьютер?
Следуйте этим шагам, чтобы установить Виндовс на компьютер:
1. Проверьте, что ваш компьютер соответствует минимальным системным требованиям для установки Windows.
2. Загрузите последнюю версию Windows на официальном сайте Microsoft или приобретите установочный диск.
3. Вставьте установочный диск в дисковод или подключите загрузочную флешку к компьютеру.
4. Перезагрузите компьютер и войдите в настройки BIOS (обычно это делается путем нажатия клавиши Del, F2 или F10 при загрузке компьютера).
5. Найдите в настройках BIOS раздел Boot (Загрузка) и задайте флешку или CD/DVD-ROM диск как приоритетный диспозитив для загрузки.
6. Сохраните изменения в настройках BIOS и перезагрузите компьютер.
7. Запустите процесс установки Windows, следуя инструкциям на экране.
8. Выберите язык и нажмите «Далее».
9. Примите лицензионное соглашение и нажмите «Далее».
10. Выберите тип установки, кастомную или обновление.
11. Выберите диск для установки Windows и нажмите «Далее».
12. Начнется установка Windows. Дождитесь завершения процесса установки.
13. Настройте начальные настройки, такие как язык ввода и временную зону.
14. Создайте учетную запись пользователя и настройте пароль.
15. Пройдите настройку сетевого подключения и настройку дополнительных параметров установки.
16. Готово! Поздравляем, вы установили Виндовс на свой компьютер.
Ссылки для загрузки Windows:
1. Windows 10 — https://www.microsoft.com/en-us/software-download/windows10
2. Windows 8.1 — https://www.microsoft.com/en-us/software-download/windows8ISO
3. Windows 7 — https://www.microsoft.com/en-us/software-download/windows7
4. Windows Vista — https://www.microsoft.com/en-us/download/windows-vista-sp2-msdn/
5. Windows XP — https://www.microsoft.com/en-us/download/details.aspx?id=25129
Обратите внимание, что некоторые старые операционные системы могут быть недоступны для загрузки с официальных сайтов, так как они больше не выпускаются. Если вам нужна такая операционная система, то можете найти ссылки на сторонних сайтах, но будьте осторожны, так как они могут быть небезопасными. Рекомендуется скачивать программное обеспечение только с проверенных и надежных источников.
Какой способ бэкапа наиболее надежный и быстрый для больших объемов данных?
Какой способ бэкапа наиболее надежный и быстрый для больших объемов данных?
Существует несколько способов бэкапа для больших объемов данных, и каждый из них имеет свои сильные и слабые стороны. Вот некоторые из них:
1. Использование внешних жестких дисков и RAID массивов — это один из наиболее быстрых способов резервного копирования больших объемов данных. RAID-массив может обеспечивать быстрое и надежное хранение данных, а также защиту от отказов жестких дисков и сбоев в системе.
2. Облачное хранение — это еще один популярный способ резервного копирования, который обеспечивает защиту данных от сбоев в работе жестких дисков. Облачное хранение также позволяет получить доступ к данным в любое время и с любого устройства с Интернет-подключением.
3. Несколько копий данных на разных устройствах — это достаточно простой, но надежный способ создания резервных копий больших объемов данных. Этот метод предполагает создание нескольких копий данных на жестких дисках, DVD, флеш-картах или других устройствах хранения их в разных местах.
Выбор наиболее надежного и быстрого способа бэкапа для больших объемов данных будет зависеть от многих факторов, включая размер данных, доступность оборудования, срок хранения и т.д.
Внешние жесткие диски и RAID массивы
Использование внешних жестких дисков и RAID массивов для резервного копирования данных является одним из наиболее эффективных способов сохранения ценных информационных ресурсов.
Внешний жесткий диск — это переносное устройство хранения данных, которое может быть подключено к компьютеру через USB, FireWire или другой интерфейс. Он может использоваться для создания копий данных и хранения их в другом месте. Кроме того, современные внешние жесткие диски обладают большим объемом памяти, что позволяет хранить большие объемы информации.
RAID (Redundant Array of Independent Disks) — это метод хранения данных, при котором используется несколько физических жестких дисков для создания одного логического диска. RAID-массивы бывают разных типов — от RAID 0 до RAID 6. В зависимости от типа используются различные стратегии хранения данных, которые могут быть нацелены на увеличение скорости чтения/записи, улучшения надежности хранения, повышения скорости доступа к информации и другие параметры.
Один из главных преимуществ RAID-массивов — это повышенная отказоустойчивость. Если один из дисков отказывает, данные не теряются благодаря их дублированию на других дисках. Кроме того, RAID-массивы обеспечивают быстрый доступ к данным, что делает их удобным способом хранения и резервного копирования информации.
В целом, использование внешних жестких дисков и RAID массивов позволяют создать надежный и быстрый способ резервного копирования больших объемов данных, что особенно важно для бизнеса и организаций, требующих постоянного доступа к хранимой информации.
Облачное хранение
Облачное хранение — это способ хранения данных на удаленных серверах (облачных хранилищах), которые могут быть доступны через Интернет. Пользователи могут загружать, сохранять, редактировать и синхронизировать данные на серверах облачного сервиса.
Одним из главных преимуществ облачного хранения является его гибкость и простота использования. Пользователи могут загружать и скачивать файлы с любого устройства, подключенного к Интернету, без необходимости использовать специальную программу или устройство хранения данных.
Также облачное хранение обеспечивает доступность данных. Если компьютер или другое устройство хранения данных выходит из строя, пользователи могут легко восстановить свои файлы с серверов облачного хранилища. Облачные сервисы зачастую предлагают автоматическое резервное копирование данных и версионность, что дополнительно обеспечивает защиту данных.
Кроме того, облачное хранение может быть более экономичным, чем покупка и поддержка собственных серверов и устройств хранения данных. Юридические лица могут использовать облачные сервисы для сокращения затрат на IT-оборудование и сопутствующую инфраструктуру.
Однако, облачное хранение данных имеет свои недостатки. Во-первых, безопасность данных может стать проблемой, поскольку данные на серверах облачных сервисов могут стать доступными для злоумышленников. Во-вторых, облачные сервисы могут быть недоступны в случае временных сбоев в работе Интернет-сети или серверов.
В целом, облачное хранение является популярным и гибким способом резервного копирования данных, обеспечивающим отказоустойчивость и доступность информации в любое время и с любого устройства с Интернет-подключением.
Другие устройства хранения данных
Создание нескольких копий данных на разных устройствах является простым и эффективным методом резервного копирования данных. В основе такого подхода лежит идея сохранения копий данных на различных устройствах в разных местах для обеспечения надежной защиты от потери или повреждения данных в случае сбоя тех или иных устройств.
Создание резервных копий просто. Для этого нужно иметь несколько носителей хранения информации, которые могут быть использованы для создания копий данных. Как правило, это жесткие диски, флеш-накопители, DVD, Blu-ray диски или другие устройства хранения данных.
Далее необходимо скопировать данные на каждый из носителей хранения. Например, можно скопировать все данные на жесткий диск, затем скопировать их на флеш-накопитель, и, наконец, на DVD-диск. Обычно данные копируются с помощью специального программного обеспечения, предназначенного для создания резервных копий.
Далее созданные копии необходимо сохранить в разных местах, чтобы обеспечить их надежную защиту от потери или утери данных. Например, можно сохранить одну копию данных на жестком диске, который хранится в офисе компании, а другую копию можно сохранить на флеш-накопителе и отправить на домашний адрес. Таким образом, в случае сбоя одного из носителей хранения данных, копия данных всегда будет доступна на другом носителе.
Кроме того, для обеспечения дополнительной надежности данные можно сохранять в зашифрованном виде. Это обеспечит дополнительную защиту от несанкционированного доступа к данным.
В целом, создание нескольких копий данных на разных устройствах является простым и надежным способом создания резервных копий больших объемов данных, который может быть использован как для индивидуальных пользователей, так и для бизнеса.
Как использовать гитхаб как хостинг сайта?
Допустим, вы сделали какой-то проект, например, собрали себе портфолио по шаблону, и теперь хотите выложить его в интернет. Если вы использовали только HTML и CSS, то необязательно платить деньги, чтобы загрузить сайт куда-то. Вы можете бесплатно выложить сайт на сервис GitHub Pages. Всё, что нужно — аккаунт на Гитхабе.
Создание репозитория
Для создания репозитория перейдите по ссылке https://github.com/new.
Важно, чтобы название репозитория было в виде «username.github.io где username — имя вашего аккаунта на Гитхабе. В нашем примере это будет evgeniyshklyar.github.io.
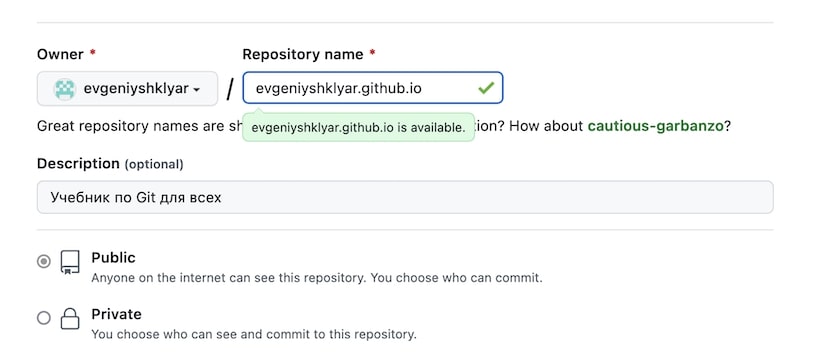
Обязательно установите галку на пункте Add a README file.
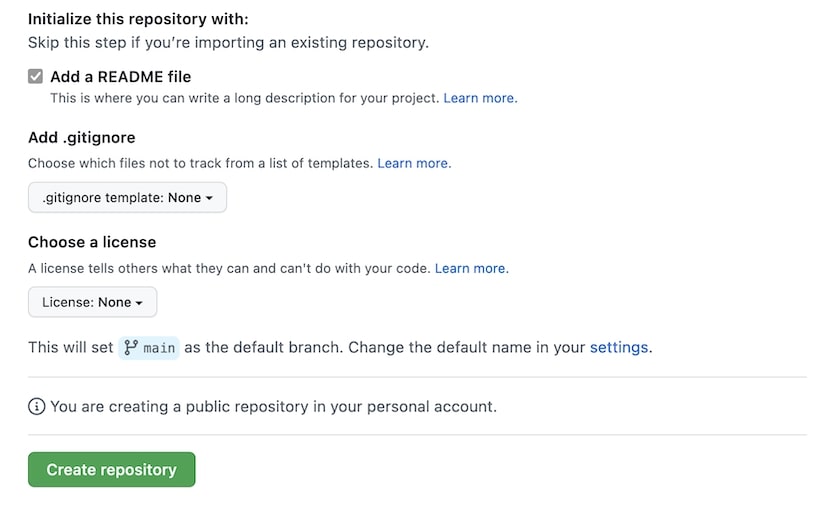
Загрузка файлов
Репозиторий создан, теперь нужно загрузить файлы. Для этого можно воспользоваться VS Code, консолью или GitHub Desktop, но в нашем случае достаточно интерфейса Гитхаба.
Нажмите кнопку Add file — Upload files.

Затем перетащим файлы в появившееся поле для загрузки.
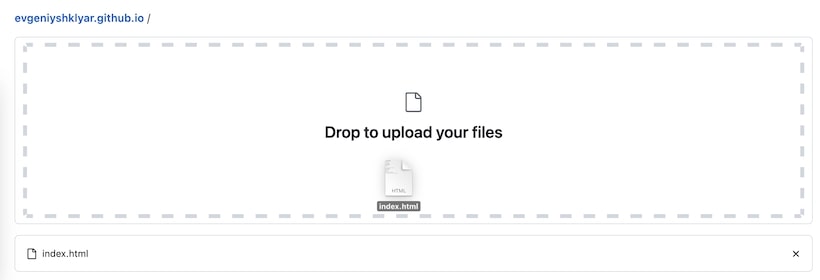
Добавим комментарий к нашему коммиту и нажмём кнопку «Commit changes».
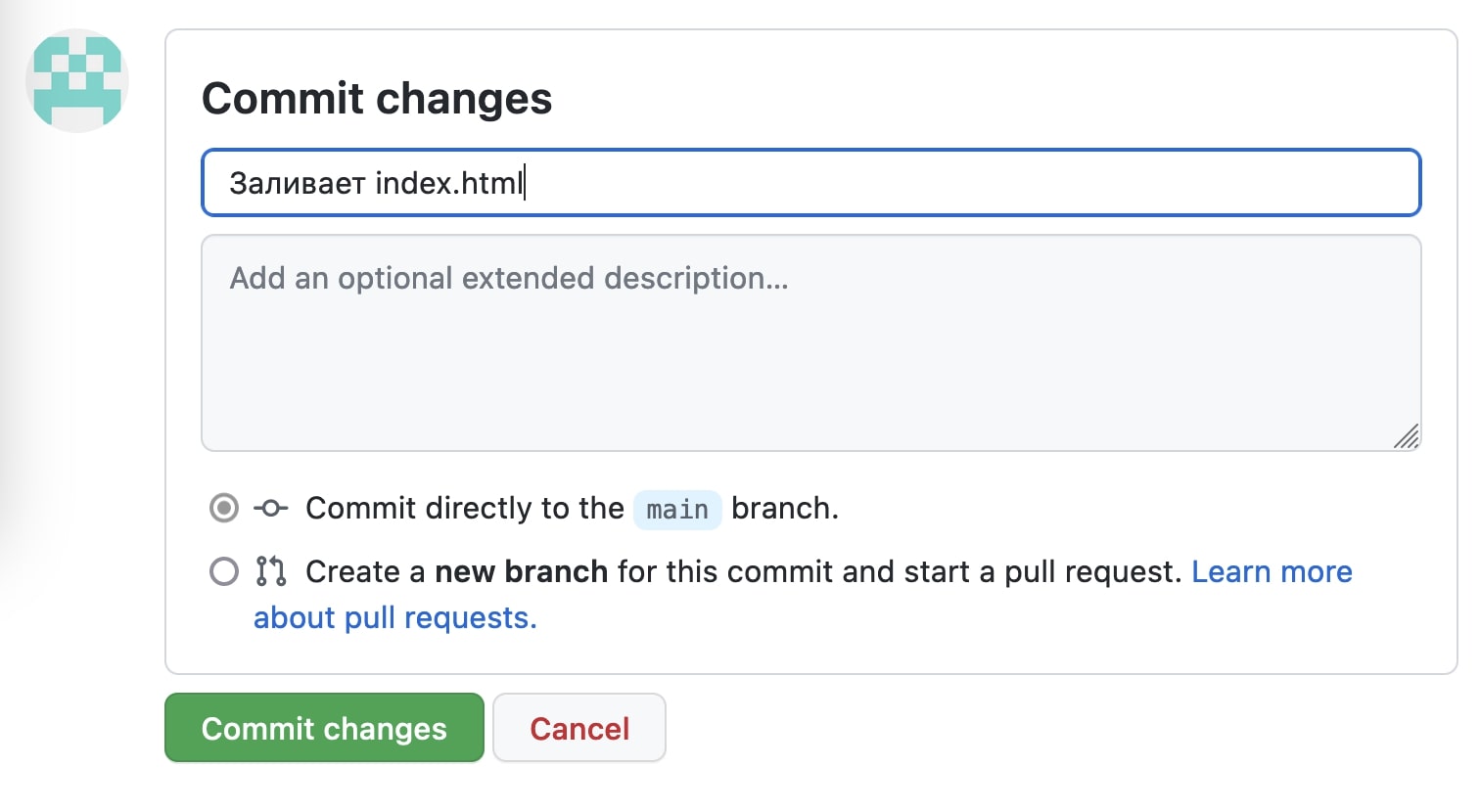
Готово! Файлы загружены в репозиторий.
Проверка работы сайта
Чтобы проверить работу сайта, достаточно перейти по адресу username.github.io, в нашем случае это htmlacademy. github.io. Вуаля!
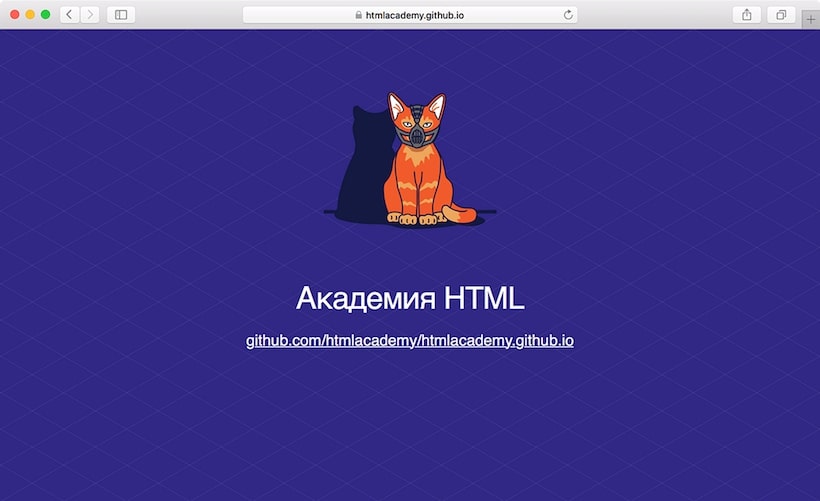
Всё хорошо, сайт работает.
Шаг 4. Подключаем свой домен
Гитхаб позволяет использовать собственное доменное имя вместо стандартного username. github.io. Для этого, разумеется, вам сначала нужно приобрести его — как это сделать, написано в другой статье.
Предположим, что у вас уже есть домен. Давайте подключим его к репозиторию. Перейдём во вкладку Settings в интерфейсе репозитория, и в разделе Pages в поле Custom domain введём название нашего домена (например: html-academy. ru) и нажмём кнопку Save.
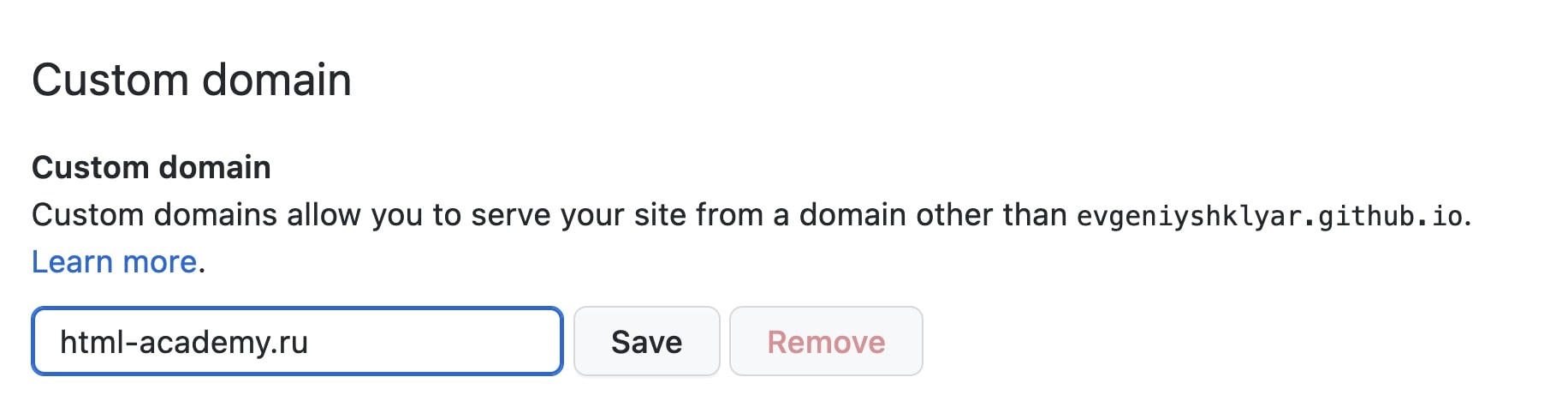
Теперь Гитхаб знает о нашем домене, однако, этого недостаточно — нужно изменить информацию о DNS-записях самого домена. Для этого нам необходимо перейти на сайт доменного регистратора, где домен был куплен. Интерфейс работы с DNS-записями разный у каждого регистратора, но суть примерно одинакова.
Нам нужно настроить A-запись домена. Для этого перейдём в панель управления DNS-записями, найдём (или добавим) A-запись и укажем 192.30.252.153 в качестве её значения. Ещё будет полезной памятка Гитхаба по настройке А-записей у DNS провайдера.
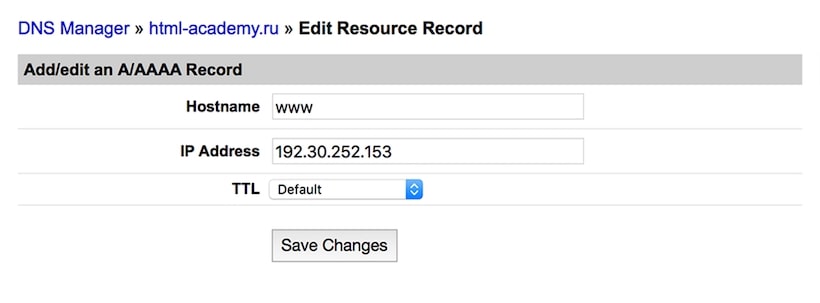
Всё готово! В течение нескольких часов вы сможете открыть свой сайт, используя ваш домен.
Как прогнозировать вероятность конверсии?
Для правильного назначения ставок важно как можно точнее вычислить вероятность конверсии для каждого ключевого слова. Однако, при небольшом числе кликов, показателю конверсии нельзя доверять - он обладает значительной погрешностью. В этой статье я приведу несколько простых методов повышения точности оценки вероятности конверсии.
Вероятность
Не следует путать показатель конверсии с ее вероятностью. Например, если у нас 1 клик и 0 конверсий, то показатель равен нулю, но это не значит что и вероятность покупки тоже нулевая.
Вероятность по определению - это частота на бесконечности. Другими словами, если бы число кликов было бы бесконечно большим, то показатель и вероятность конверсии были бы равны. При большом числе кликов эти два числа примерно равны. Но при малом - они могут существенно отличаться.
Погрешность
Благодаря теории вероятности, легко вычислить среднюю погрешность которую имеет показатель конверсии. Это число показывает, на сколько, в среднем, показатель конверсии отличается от ее вероятности:
σ=√((p(1-p))/n)
Где p вероятность конверсии, n - число кликов. Например, при конверсии = 1% и 100 кликах мы получаем
σ=√((1% * 99%)/100) ≈0.995%
На первый взгляд, это небольшая погрешность, но искомое число (вероятность конверсии) тоже мало и по условиям примера равно 1%. Другими словами, при 100 кликах погрешность примерно равна показателю конверсии.
Поэтому, для наглядности, перейдем к относительной погрешности, разделив погрешность на вероятность конверсии. Получим 99.5%.
Формула для относительной погрешности:
σ/p=√((p(1-p))/n)/p=√((p*(1-p))/(p^2*n))=√(((1-p))/pn)
Мы можем рассчитать относительную погрешность в зависимости от числа кликов и показателя конверсии. Получим:
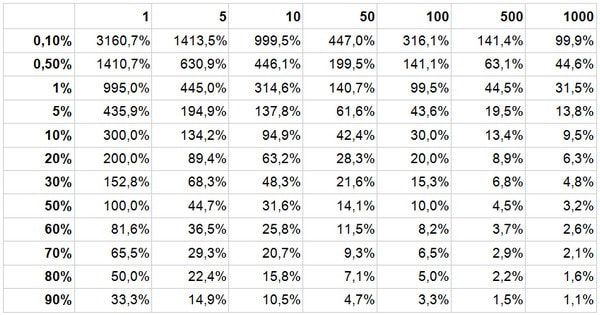
Легко видеть, что при низком числе кликов погрешность получается просто астрономической. При одном клике и 1% конверсии относительная погрешность равна 995,0%. То есть, погрешность почти в 10 раз превышает вероятность конверсии.
На самом деле это оценка погрешности снизу. В реальности погрешность будет выше, поскольку на показатель конверсии может повлиять, например, то, что по чистой случайности все 5 кликов ключевого слова произошли ночью.
Пулинг
Как мы выяснили, в большинстве случаев, полностью полагаться на показатель конверсии нельзя. Нам нужно найти дополнительный источник информации. Самый очевидный способ - использовать показатель конверсии объявления, кампании или URL.
В статистике это называется пулингом (от английского to pool - объединять). Более понятный термин - усреднение, мы усредняем данные ключевого слова и некоторой группы ключевых слов, например, объявления. Чем больше у ключевого слова кликов, тем меньше мы усредняем.
В статистике для оценки вероятности принято использовать бета-биномиальную модель. Ее, например, использует Marin Software, если верить их патенту.
Вероятность конверсии ≈(Конверсии + A)/(Клики + A/M )
M - показатель конверсии объявления
A - степень пулинга, некоторое число. Выражает степень сходства ключевых слов в группе.
Степень пулинга, по сути, это тот объем информации, который несет группа, и которую мы добавляем к информации ключевого слова. В статистике А принято измерять в псевдоуспехах или, в нашем случае, псевдоконверсиях. Отношение А/М это число псевдонаблюдений или, в нашем случае, псевдокликов.
В итоге эту формулу легко запомнить: конверсии + псевдоконверсии, деленные на клики + псевдоклики.
Мягкий пулинг
Теоретическая оценка снизу A=1. Что подтверждается практикой. За исключением больших интернет-магазинов, которые торгуют всем - от памперсов до холодильников. Если у них за группу принять все их ключевые слова, то оптимальный A около 0.7. И даже в этом случае, 0.7 ближе к 1 чем к 0. Следовательно, мягкий пулинг не хуже, чем полное отсутствие пулинга.
В итоге наша формула:
Вероятность конверсии ≈(Конверсии + 1)/(Клики + 1/M )
Например, в объявлении показатель конверсии равен 1%, у ключевого слова было 100 кликов и 2 конверсии. Тогда оценка будет равна (2+1)/(100+1/1%)= 3/200 = 1.5%.
Другой пример: у ключевого слова было 10 кликов и ни одной конверсии, оценка равна (0+1)/(10+ 1/1%)=1/110=0.91%
Чтобы понять адекватность этого метода, мы построим таблицу:
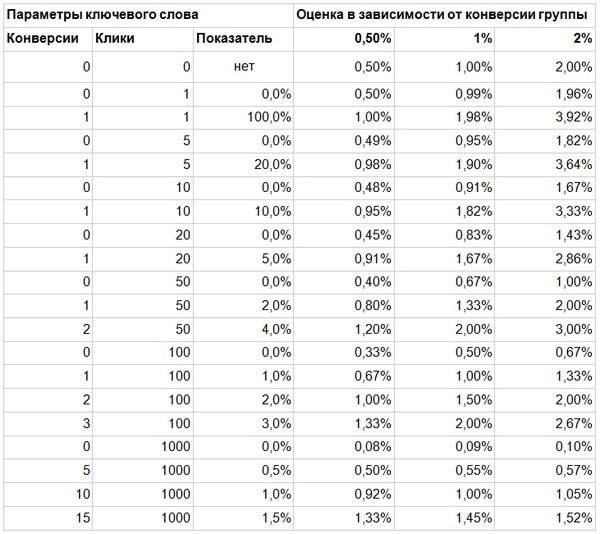
Как мы видим, оценки получаются довольно адекватными. При небольшом числе кликов, оценка - значительно лучше показателя конверсии, при большом - они почти не отличаются.
Мы можем посчитать максимальную погрешность, которая будет при мягком пулинге и сравнить ее с погрешностью без пулинга:
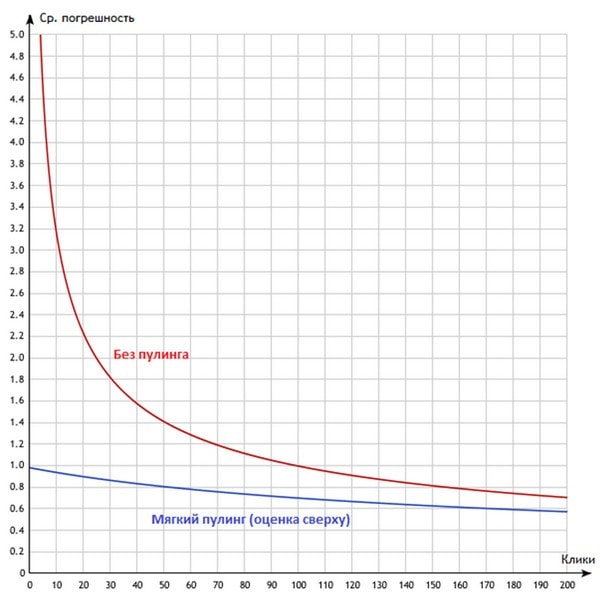
Многоуровневый пулинг
Показатель конверсии объявления тоже обладает довольно высокой погрешностью. Поэтому его тоже можно «пулить» и использовать это оценку для расчета ключевого слова.
Например, показатель конверсии у кампании 1%. У объявления 300 кликов и 2 конверсии. У ключевого слова была 1 конверсия и 70 кликов. Считаем оценку вероятности конверсии объявления (2+1)/(300+1/1%)=3/400=0.75%. Используем оценку объявления для оценки конверсии ключевика (1+1)/(70+1/0.75%)=2/203=0.985%
Таблица
По этой ссылке таблица в Google Docs, которая оценивает вероятность конверсии методом многоуровневого пулинга. Скопируйте ее себе на Google диск или сохраните как файл для Microsoft Excel.
В таблице есть четыре уровня: Аккаунт (все ключевые слова), Кампания, Объявление и Ключевое слово. Названия уровней условные. К примеру, вы можете, вместо объявления подставить URL.
Более того, можно посчитать оценку не только вероятности конверсии, но и, например, вероятность отказа. Нужно просто подставить вместо числа конверсий число отказов.
Проще всего посчитать данные по мягкому пулингу. Для этого нужно просто скопировать в таблицу данные по ключевым словам.
Также эта таблица считает погрешность, которую вы можете снизить, подобрав оптимальную степень пулинга. Для этого нужно вставить статистику по двум периодам.
В общем, чтобы подобрать степень пулинга, нужно:
- Разбить данные на два непересекающихся периода. Например, весна и лето 2015 года и вставить эти данные в таблицу.
- Попробовать изменить степень пулинга «Объявление->Ключевик» (H4). так чтобы минимизировать ошибку (D9)
- Попробовать изменить степень пулинга «Кампания->Объявление» (F4). так чтобы минимизировать ошибку (D9)
- Попробовать изменить степень пулинга «Аккаунт-> Кампания» (D4). так чтобы минимизировать ошибку (D9)
- Вернуться на второй шаг и еще пару раз пройти этот цикл. И, в конечном итоге, вы найдете оптимальные коэффициенты пулинга. Это может занять до получаса, но для каждого сайта это нужно сделать один раз в жизни.
- Вставьте суммарные данные за весь период, и таблица посчитает довольно точные оценки конверсии.
Ошибка (D9) даже при идеальном прогнозе никогда не будет нулевой. Дело в том, что в контрольном месяце число кликов не бесконечно велико, а мы сравниваем наш прогноз с показателем конверсии контрольного месяца, который отражает вероятность конверсии с очень большой погрешностью.
Поэтому снижение ошибки, например, с 40% до 36% повысит эффективность ставок намного выше, чем на 10%.
Регрессионный анализ
В математической статистике есть целый раздел, который изучает взаимосвязь между переменными и позволяет предсказывать значение одной переменной при наличии известных значений других. Этот раздел называется «регрессионным анализом».
Допустим, у нас конверсия равна 1%, а показатель отказов около 50%. Используя таблицу, данную в начале статьи, можно понять, что погрешность у показателя отказов в 10 раз ниже, чем у показателя конверсии при одинаковом числе кликов.
При этом, эти переменные имеют сильную обратную корреляцию. В зависимости от сайта - от 60% до 90%. Грубо говоря, это значит, что мы можем восстановить вероятность конверсии с точностью 60%-90%, зная вероятность отказов.
В общем, мы можем в несколько раз снизить погрешность оценки конверсии, благодаря добавлению информации, которую несет показатель отказов.
Но для этого нужно построить статистическую модель. Благодаря формуле полной вероятности, мы можем разложить вероятность конверсии так:
P[конверсия]=K *(1-P[отказ])
Где:
P[конверсия] - вероятность конверсии
P[отказ] - вероятность отказа
K - вероятность того, что произойдет конверсия, в случае если не было отказа.
Для простоты предположим, что K - это некоторая постоянная, одинаковая для всех ключевых слов. Это предположение может показаться довольно грубым, но на практике даже такая простая модель обладает довольно высокой точностью.
K можно оценить как:
K≈(показатель_конверсии_аккаунта)/(1 - показатель_отказов_аккаунта )
P[конверсия]≈(показатель_конверсии_аккаунта)/(1 - показатель_отказов_аккаунта ) *(1-P[отказ])
Вероятность отказа мы можем оценить с помощью пулинга. Нужно просто в таблицу, вместо числа конверсий, подставить число отказов. Далее, подставим оценку вероятности отказа в эту формулу и получим еще одну оценку конверсии. Назовем ее оценкой по отказам.
Взвешенная оценка
Оценку по отказам можно объединить с оценкой полученной из пулинга. И, таким образом, получить финальную оценку с погрешностью меньшей чем у двух промежуточных оценок. Например, так:
Финальная_оценка = w * Оценка_из_пулинга + (1-w) * Оценка_по_отказам
Где w - число от 0 до 1 и подбирается также как и степень пулинга, путем минимизации погрешности оценки. Для этого в той же таблице есть второй лист. Вы можете скопировать туда две оценки и подобрать w так, чтобы минимизировать погрешность.
Итоговая оценка будет лучше, чем пулинг, и лучше, чем оценка по отказам. Ну, по крайней мере, не хуже. Например, если оценка по отказам будет очень плохой, намного хуже пулинга, то оптимальный w будет равен 1. И итоговая оценка будет равна оценке пулинга.
Динамическое взвешивание
Проблема прошлого метода в том, что w не зависит от числа кликов. Хотя оценка из пулинга точнее для высокочастотных ключевых слов, а оценка по отказам - для низкочастотных.
Мы учли это на четвертом листе. Там тоже нужно подобрать только один коэффициент – S, относительную систематическую погрешность модели. Благодаря первому листу, оцените пулингом вероятность конверсии и скопируйте оценку и ее ожидаемую погрешность на четвертый лист. Благодаря первому листу, оцените пулингом вероятность отказа и скопируйте оценку и ее ожидаемую погрешность на четрвертый лист. Подберите настройку S таким образом, чтобы минимизировать средневзвешенную относительную ошибку.
Модель скрытых отказов
Показатель отказов занижен. Поскольку тот факт, что пользователь перешел на вторую страницу, не говорит о том, что он был заинтересован в вашем товаре или услуге. Он это мог сделать из праздного любопытства, или, не поняв, что ему конкретно предлагают.
Предположим, что существует некоторый скрытый показатель отказов. Вероятность ложно отрицательного срабатывания счетчика отказов. Когда к вам пришел незаинтересованный пользователь и счетчик отказов не определил такого пользователя.
В общем: Показатель отказов занижен. Это влияет на качество прогноза. Мы можем это влияние компенсировать, построив модель. Параметры модели можно подобрать так чтобы качества прогноза было максимально высоким.
Очевиден тот факт, что чем больше явных отказов, тем больше должно быть скрытых. С другой стороны, как и любая другая вероятность, вероятность скрытого отказа должна быть меньше 1. Поэтому можно построить следующую модель:
P[скрытый отказ] = erf(L * P[отказ])
Где L некоторая положительная константа. А erf - это функция ошибки. Она всегда меньше 1. Эта функция есть в Екселе.
В итоге получим:
Вероятность конверсии = K * (1 - P[отказ]) * (1-erf(L * P[отказ]))
Где K и L подбираются уже знакомым нам способом минимизации погрешности. Первоначальный K можно взять из прошлого метода, а в качестве начального - использовать L = 0.5. Для этого в таблице есть третий лист.

Модель скрытых отказов довольно хорошо описывает реальные данные. В ней всего два параметра. Практика показывает, что эта модель работает также хорошо, как и модели, основанные на полиноме с 4-6 параметрами.
Взвешивание по обратной дисперсии
Вот финальная схема для довольно точной оценки конверсии: Считаем пулингом (первый лист) оценку конверсии и копируем оценку и ошибку на четвертый лист. Считаем пулингом (первый лист) оценку вероятности отказа. Мы копируем ошибку на четвертый лист, а оценку --на третий лист. Считаем третий лист и копируем полную вероятность отказов в четвертый лист, как оценку вероятности отказов. Считаем четвертый лист и получаем довольно точную оценку вероятности конверсии.
Заключение
Данная схема является наиболее точной из тех, что можно посчитать вручную без специфических знаний в матстатистике.
В автоматических системах вроде К50 и Marin Software используются несколько более сложные схемы пулинга, но без элементов регрессионного анализа. Качество их прогноза, скорей всего, будет выше, чем у этой схемы, но не намного. Все эти системы экономят массу времени и избавляют от человеческих ошибок.
Мы в К50 Labs используем более сложные модели. Поэтому, оценку погрешности описанного в статье метода мы посчитали только для 1 клиента. Мы взяли 10 тысяч ключевых слов из статистики одного крупного рекламодателя и разделили данные на 3 периода: два периода по месяцу для обучения и один длиной полгода для теста.

- Показатель конверсии. Мы считаем что показатель конверсии=вероятности конверсии.
- Пулинг с подбором - первый лист в таблице.
- Взвешенная оценка - итоговый метод из этой статьи. Но для ускорения работы подбор коэффициентов автоматический, в R Studio.
- K50 Labs - это индивидуальная статистическая модель сделанная мной в R Studio. Она заточена под этот сайт. Кроме отказов были использованы следующие данные:
- Текст ключевого слова (длина, число слов, наличие слов купить/цена и прочих).
- CTR в спецразмещении и гарантии и их отношение (как признак горячих тематик).
- Цены клика на поиске в зависимости от позиций
- Время и глубина просмотра
- Время добавления ключевого слова (оценка по ID)
- MCMC Sampling - это примерно такая же модель, но в Stan Sampler. Считается все точнее, но нужно очень много вычислительной мощности - расчет занял 8 часов для 10К ключевых слов. Поэтому этот метод мы использует только в исключительных случаях.
- Теоретический минимум возникает, поскольку у нас тестовый период не равен бесконечности и, поэтому, показатель конверсии на нем не равен вероятности. В скобках погрешность минус теоретический минимум, это число лучше отражает реальную погрешность.
Автор: Андрей Белоусов
Как использовать скрипты Google Sheets — APSS SCRIPT: операции с таблицей, листом, ячейкой, диапазоном, меню, событиями
Этот пост будет актуальным для тех, кто хочет писать скрипты в гугл таблице (макросы) для себя или зарабатывать на этом. . Готовые фрагменты помогут быстрее справиться с разными задачами по написанию макросов.
Рассмотрим такие вопросы:
- Операции с таблицей
- Операции с листом
- Операции с ячейкой
- Операции с диапазоном
- Создание своего меню
- Работа с событиями гугл таблицы
- Готовые решения, наработки, примеры кода.
Операции с таблицей
Для того, чтобы програмно работать с таблицей, нужно к ней обратиться. Рассмотрим несколько способов.
Обратимся к активной таблице (в которой работаем в текущий момент). Для этого используем конструкцию:
let ss = SpreadsheetApp.getActiveSpreadsheet();
В результате мы сможем обращаться к нашей таблице, сославшись на переменную ss. Например, обратиться к активному листу (что открыт у вас в текущий момент):
let activeSheet = ss.getActiveSheet();
У нас в переменной activeSheet будет ссылка на активный лист таблицы
Также в гугл-таблице можна обратиться по ее идентификатору или по ссылке на таблицу.
Я предпочитаю использовать идентификатор.
Это может пригодиться, если вы работаете в одной таблице и вам нужно воспользоваться данными из другой (что-то взять, изменить и пр.). Привожу пример кода:
let ss = SpreadsheetApp.openById('идентификатор таблицы'); //используем идентификатор
let ss = SpreadsheetApp.openByUrl('ссылка на таблицу'); //используем ссылкуТочно, как и в предыдущем случае, в переменной ss находится ссылка на таблицу и в дальнейшем можно ее использовать.
Как можно заметить, во всех вышеперечисленных случаях мы используем специальный класс SpreadsheetApp. Он имеет много различных методов и свойств, например можно создать новую таблицу (SpreadsheetApp.create(«имя нового файла»);) и т.п.
Операции с листом.
Прежде, чем работать непосредственно с данными, нам нужно обратиться к листу, где собственно эти данные находятся. Здесь также имеем несколько способов.
1. SpreadsheetApp.getActiveSpreadsheet().getSheets()[0]
Обращаемся к коллекции листов в активной таблице и берем первый (нумерация начинается с нуля)
2. SpreadsheetApp.getActiveSpreadsheet().getActiveSheet()
Обращаемся к активному листу
3. SpreadsheetApp.getActiveSpreadsheet().getSheetByName("Лист1")Обращаемся к листу по имени (в примере «Лист1»).
Естественно, что подобными способами вы можете обращаться к листам в другой (не активной) таблице. Но есть один нюанс, который касается способа номер 2 (обратиться к активному листу).
Если вы обращаетесь к другой таблице (открываете по идентификатору или ссылке) и обращаетесь к активному листу (getActiveSheet()), вы получаете первый лист, даже если при этом таблица будет открыта у вас в соседней вкладке на нужном вам листе. Поэтому, лучше четко обозначать лист, к которому вы обращаетесь (либо по имени, либо по номеру).
Операции с ячейкой.
Обращаемся к ячейке.
1. let myCell = sheet.getRange("A1");2. let myCell = sheet.getRange(1,1);
3. let myCell = sheet.getActiveCell();
4. let myCell = sheet.getActiveRange();
В первом варианте мы обращаемся с ячейке «A1», указав явно ее адрес (А1), во втором используем номер строки и колонки (1-я строка, 1-я колонка). Сначала указываем номер строки, затем номер колонки.
Т.е., чтобы обратиться к первой ячейке в третьей строке, нужно указать (3,1).
Предпоследний и последний способ — получить ячейку, активную (выделенную) в текущий момент.
В последнем случае в переменную попадет выделенный диапазон (если вы выделите именно диапазон (блок ячеек). Про диапазоны и работу с ними будет чуть дальше.
Как вы могли догадаться, в переменной sheet лежит ссылка на лист, которую мы можем получить одним из способов, указанных выше.
Теперь, когда мы имеем в переменной myCell нашу ячейку, мы можем делать с ней ряд действий, например.
1. Вписать в ячейку нужное значение:
myCell.setValue("Новое значение");Вписываем в нашу ячейку строку «Новое значение»
2. Получить текущее значение ячейки:
let a1 = myCell.getValue();
Сохраняем в переменную a1 значение ячейки A1
Обратите внимание, что в первом случае используется метод setValue (от англ. установить значение), во втором — getValue (от англ. взять значение).
В дополнение к сказанному. Есть метод «getDisplayValue», который возвращает значение ячейки в том виде, в каком их видно на экране. Это значит, что если вы например применили к числу форматирование и видите на экране в ячейке что-то типа «1 078 234,13», то вы это же и получите в переменной, если используете «getDisplayValue». Это также касается и использования форматирования для ячеек с датой и временем. Однако, не все так просто и могут быть нюансы.
Как и что использовать, решать вам. Я же предпочитаю получать значения, как есть, с помощью «getValue», а уже потом, после обработки, при выводе полученных значений на лист форматировать так, как необходимо для задачи.
Продолжим. С помощью специальных методов можно установить фон заливки ячейки:
myCell.setBackground("yellow"); //закрасить в желтыйи узнать фон заливки ячейки:
Logger.log(myCell.getBackground()); //получить цвет заливки и вывести полученное значение в консоль
В данном примере я использовал директиву Logger.log для вывода информации в консоль. Это иногда очень удобно при отладке программного кода. Хочу обратить ваше внимание, что цвет заливки выводится в формате #ffff00 (соответствует желтому цвету).
Подобными способами можно изменить форматирование нашей ячейки, размер шрифта и все остальное, что возможно сделать с ячейкой в гугл-таблице.
Список всех доступных методов открывается, когда вы в редакторе кода после переменной с ссылкой на нашу ячейку ставите точку.
Таким образом можно получить доступные методы и свойства для всех объектов, которым соответствует ранее назначенная переменная.
Пояснение. К примеру, если вы ранее в коде в переменную myVar сохранили ссылку на лист, то можно получить список всех доступных методов и свойств листа, поставив в редакторе после имени переменной точку ( myVar. ).
В завершении текущего блока хочу поделиться небольшим «лайфхаком».
Один из способов что-то узнать, если забыл (или просто не знаешь), использовать встроенный инструмент «Записать макрос».
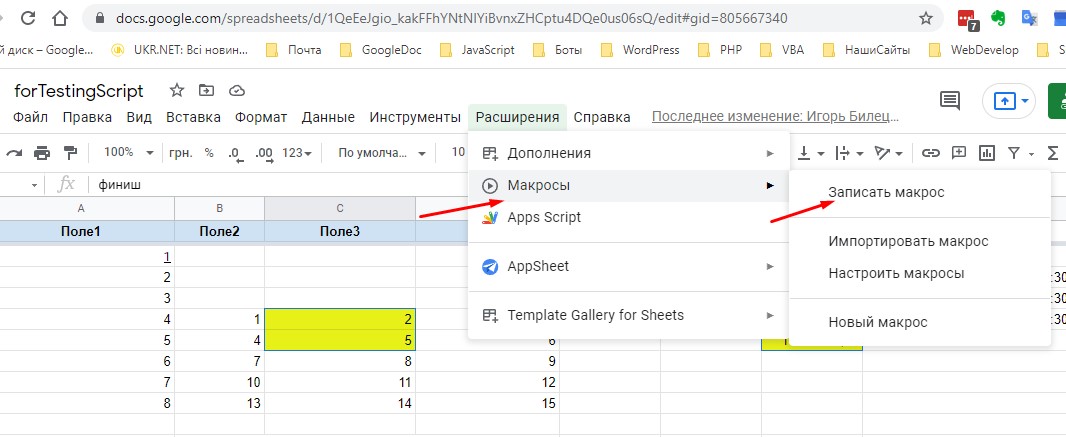
Вы записываете макрос с нужными вам действиями (что хотите реализовать с помощью скрипта, но не знаете как) и затем сохраняете его.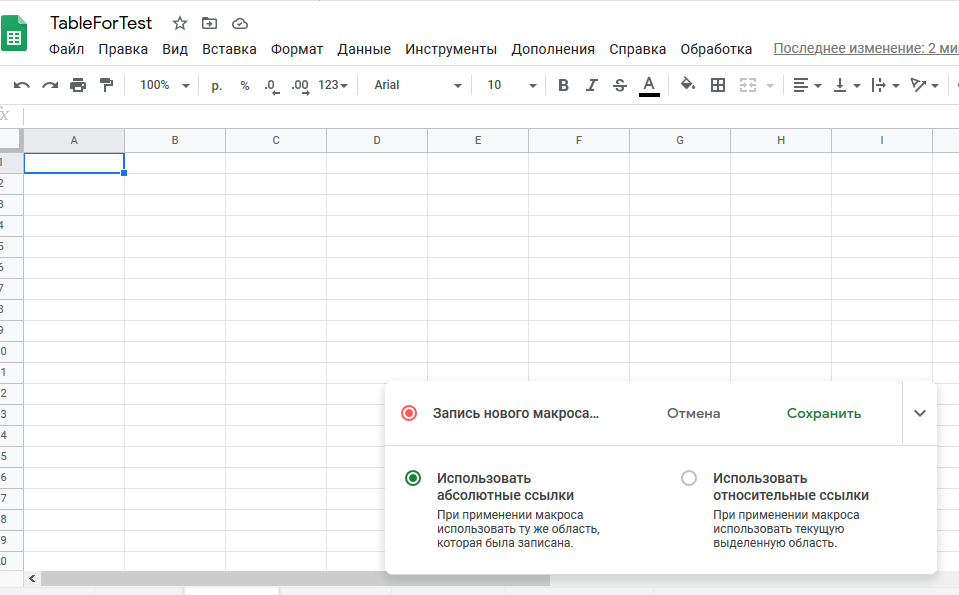

Теперь вы можете открыть код макроса и подсмотреть, что и как реализуется. Я иногда пользуюсь таким способом, чтобы быстро что-то узнать
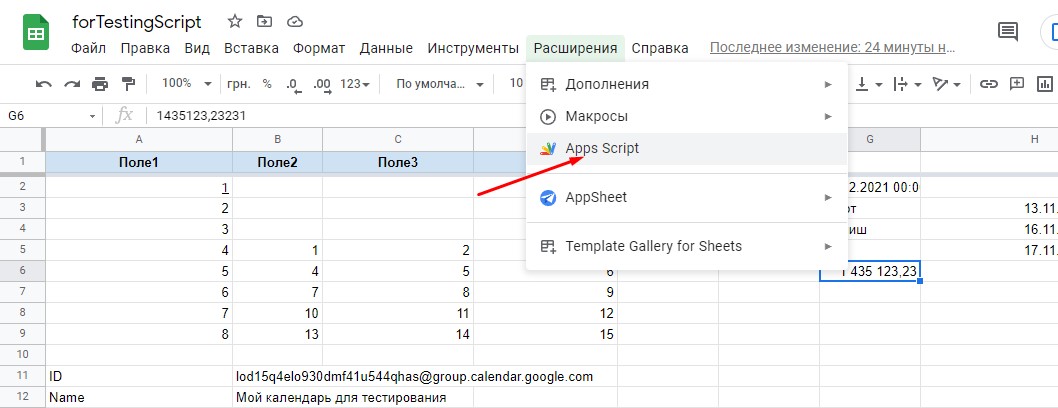
Примечание. Чтобы открыть редактор скриптов, необходимо воспользоваться пунктом меню «Расширения -> Apps Script»:
.
Операции с диапазоном.
Обратиться к диапазону.
let myRange = sheet.getRange(1,1,2,3);
Получаем в переменной myRange нужный диапазон.
Расшифровка. В переменную myRange попадает диапазон c началом в ячейке с координатами (1,1) и окончанием в ячейке с координатами (2,3) — вторая строка, третья колонка.
Важное уточнение. В директиве getRange указывается: номер строки (начало диапазона), номер колонки (начало диапазона), кол-во строчек (размер диапазона по вертикали, кол-во колонок (размер диапазона по горизонтали).
К примеру, если мы получаем нужный диапазон вот-так:
let myRange = sheet.getRange(3,4,10,5);
То наш диапазон имеет координаты (3 — номер строки (начало), 4 — номер колонки (начало), 12 — номер строки (конец), 8 — номер колонки (конец).
Почему не 13-я строка, а 12-я? Потому что, размерность по вертикали — 10. От строки номер 3, включая саму строчку номер 3 — 12 строка — как раз выходит 10 строчек. По горизонтали — то же самое.
Иногда, чтобы на первых порах не путаться, где начинается и заканчивается диапазон, можно для тестирования закрасить диапазон (например, в желтый), чтобы визуально убедиться, что мы определили размерность диапазона правильно:
myRange.setBackground("yellow");Закрасим диапазон желтым и посмотрим, правильно или нет определились с размерами
Иногда необходимо обработать диапазон, у которого нижняя граница — динамическая (постоянно меняется). Например, табличка со списком клиентов, который постоянно меняется. Как нам в таком случае получить наш диапазон?
На помощь приходит метод, который позволяет получить номер последней строки, где на листе есть данные — «getLastRow» (получить последнюю строчку). Как вы помните, в методе getRange предпоследним параметром идет кол-во строк (размер диапазона по вертикали).
Если в нашей условной табличке со списком клиентов данные начинаются со второй строки (в первой — оглавление таблицы), то кол-во строк в таблице равно getLastRow() — 1.
Для определения правой границы таблицы можна воспользоваться getLastColumn — номер последнего столбца с данными (крайний правый).
Еще вариант, как получить динамический диапазон, если вы знаете его границы по ширине:
К примеру, у вас таблица заканчивается (правая граница) на колонке F. В таком случае получить диапазон:
let myRange = sheet.getRange("A2:F" + sheet.getLastRow()).getValues();В результате мы в переменной myRange получим все значения нашего динамического диапазона (учитываем, что в первой строке идут названия столбцов таблицы, поэтому начинаем с A2).
В отличии от работы с ячейкой, работа с диапазон имеет ряд нюансов. Рассмотрим подробнее.
Во первых, диапазон — это, как правило, несколько значений. Поэтому и работа с ними отличается от работы с ячейкой.
В зависимости от задачи, мы можем работать с диапазоном напрямую (в нашем примере с помощью переменной myRange), либо сразу считать значения из диапазона в массив и затем работать со значениями.
Если мы работаем напрямую с диапазоном (с помощью объекта Range), мы имеем по сути массив, каждым елементом которого есть ячейка, которая входит в наш диапазон.
Соответственно, мы имеем доступ ко всем свойствам ячейки — значение, цвет заливки и пр. Например, чтобы получить значение левой верхней ячейки, необходимо написать:
let a1 = myRange.getCell(1,1).getValue();
В результате в переменной a1 имеем значение ячейки с координатами 1,1 (левой верхней ячейки)
Соответственно, что-то записать в левую верхнюю ячейку можно так:
myRange.getCell(1,1).setValue("Новое значение");Подобным способом можно работать и с остальными свойствами ячеек в нашем диапазоне.
Получить диапазон также можно и неявным способом (не зная конкретных размеров). Например, если пользователь выделил произвольный диапазон на листе, то получить его можно с помощью метода:
let myRange = sheet.getSelection().getActiveRange();
На всякий случай напоминаю, что в переменной sheet лежит ссылка на наш активный лист.
Перебрать все элементы нашего диапазона (читай, ячейки) можно с помощью цикла.
Вначале нам необходимо узнать размеры нашего диапазона — кол-во строчек и столбцов. Для этого есть методы «getNumRows» (получить кол-во строк) и «getNumColumns» (получить кол-во столбцов).
Напишем код:
let myRange = sheet.getSelection().getActiveRange(); //получаем выделенный диапазон
let k = 1; //просто переменная для тестирования
for (let i = 1; i <= myRange.getNumRows(); i++) { //перебор всех строчек
for (let j = 1; j <= myRange.getNumColumns(); j++) { //перебор всех столбцов
myRange.getCell(i,j).setValue(k); //задаем значение очередной ячейки диапазона
k += 1; //увеличиваем нашу переменную на единицу (еще один из способов)
}
}В приведенном коде мы перебираем подряд все ячейки выделенного диапазона и каждой присваиваем значение — от 1 до общего кол-ва ячеек в нашем диапазоне.
Конечно же, вместо присвоения ячейке нового значения можно воспользоваться другим методом работы с текущей ячейкой (исходя из вашей задачи).
Иногда приходиться работать с большими диапазонами, сравнивать несколько диапазонов и прочее. В таких случаях более оптимальным решением есть сохранить содержимое диапазонов в массивы и работать с массивами (по сути обрабатывать данные в оперативной памяти).
По факту мы вначале загружаем все необходимые диапазоны с данными в массивы, затем выполняем определенные операции и по завершению обработки выгружаем в таблицу (или куда-то передаем) полученный результат.
Так получается намного быстрее. А учитывая тот факт, что время работы скрипта ограничено 6-ю минутами, иногда это важно для решения определенных задач.
Я отмечу, что для того, чтобы считать значения диапазона в массив, необходимо использовать метод «getValues».
Например, сохраним в массив выделенный диапазон:
let myArray = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet().getSelection().getActiveRange().getValues();
Или более читабельный вариант (учитывая созданные ранее переменные)
let myRange = sheet.getSelection().getActiveRange(); //получаем выделенный диапазон let myArray = myRange.getValues(); //сохраняем значения диапазона в массив
Данным кодом мы в переменную myArray получили значения выделенного диапазона на активном листе активной таблицы.
Создание своего меню
Запускать тот или иной скрипт удобно с помощью пользовательского меню. Конечно же, можно запустить скрипт непосредственно из редактора скриптов, либо при наступлении определенного события, клике на картинке и пр.
В данном разделе коснемся создания своего меню.
В гугл таблицах пользовательское меню бывает двух типов:
- пользовательское меню — создается, как отдельное меню
- дополнительное меню — пункт меню, который можно добавить в уже существующее на листе меню «Дополнения»
Скриншот обычного меню:

Скриншот дополнительного меню:
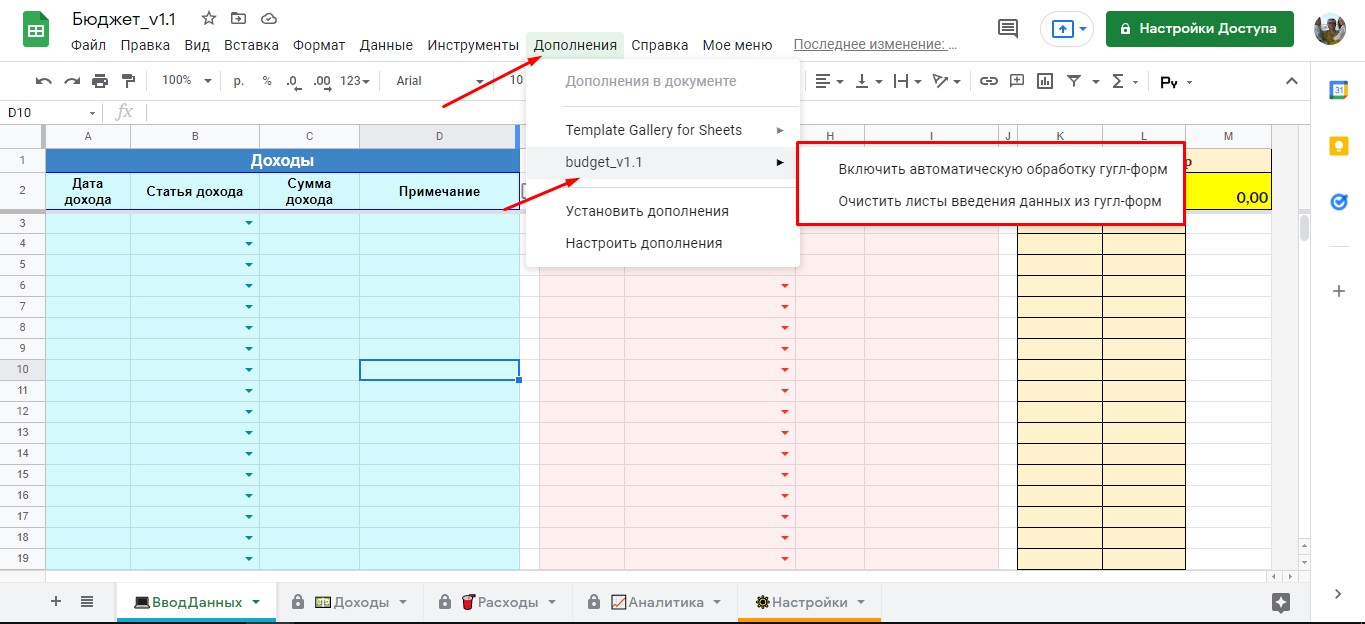
Когда и какие виды меню использовать — зависит от поставленных задач. От себя добавлю, что меню создается с помощью скрипта. Часто скрипт, который создает требуемое меню, запускается при открытии гугл таблицы — используя специальное событие «открытие таблицы».
Далее коснемся вопроса работы с событиями гугл таблицы.
.
Работа с событиями таблицы
Когда что-то происходит с таблицей или данными, то возникает так называемое событие.
Например, когда вы открываете таблицу, либо редактируете данные, возникает событие «Открытие таблицы» или «Редактирование таблицы» соответственно.
Следовательно, вы можете использовать событие — запустить нужный вам скрипт.
Что здесь имеется ввиду. Например, когда вы открываете таблицу — срабатывает событие, которое в свою очередь запускает нужный скрипт, например создание пользовательского меню.
Для того, чтобы в определенное событие запустился определенный скрипт, необходимо либо создать специальную функцию с четко установленным именем (которое определено разработчиками гугл таблиц), либо создать специальный триггер, который сработает при возникновении события и запустит заданную вами функцию.
Источник: https://forbiz-online.org/skripty-google-sheets-tablicej-listom-yachejko...
Как использовать Order By в гугл таблицах формулы QUERY?
Вы можете использовать следующий синтаксис, чтобы упорядочить результаты запроса Google Sheets по определенному столбцу:
= query ( A1:C12 , " select A, B order by B asc", 1 )
В этом примере мы выбираем столбцы A и B и упорядочиваем результаты по столбцу B по возрастанию. Мы также указываем 1 , чтобы указать, что в верхней части набора данных есть 1 строка заголовка.
Вы также можете использовать следующий синтаксис для упорядочения по нескольким столбцам:
= query ( A1:C12 , " select A, B order by B asc, A desc", 1 )
В этом примере мы выбираем столбцы A и B и упорядочиваем результаты по столбцу B по возрастанию, а затем по столбцу A по убыванию.
Следующие примеры показывают, как использовать эти формулы на практике.
Пример 1: Упорядочить по одному столбцу по возрастанию
Мы можем использовать следующую формулу для выбора столбцов «Игрок» и «Команда», а затем упорядочить результаты по командам в порядке возрастания:
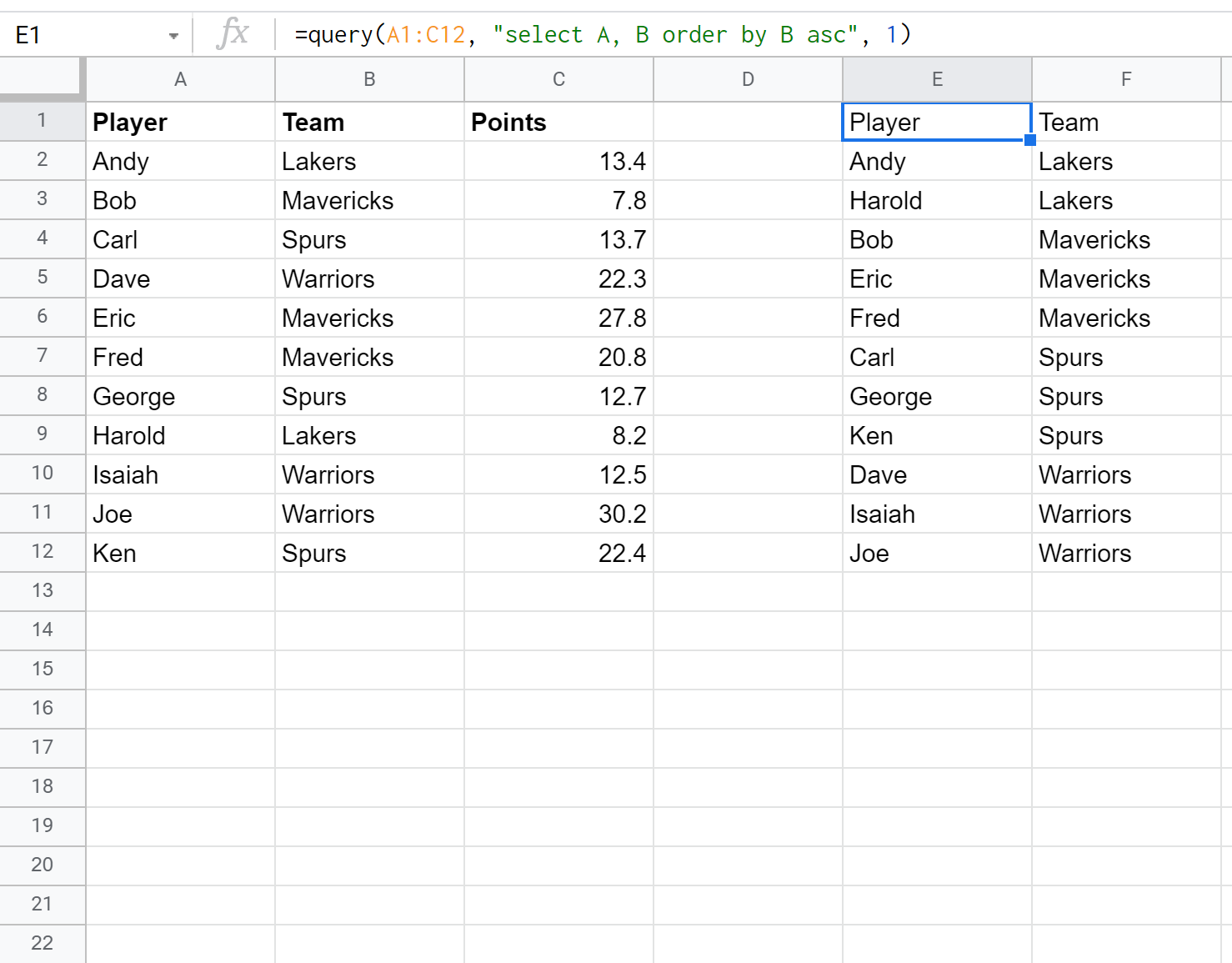
Пример 2: Упорядочить по одному столбцу по убыванию
Мы можем использовать следующую формулу, чтобы выбрать все столбцы и упорядочить результаты по точкам в порядке убывания:
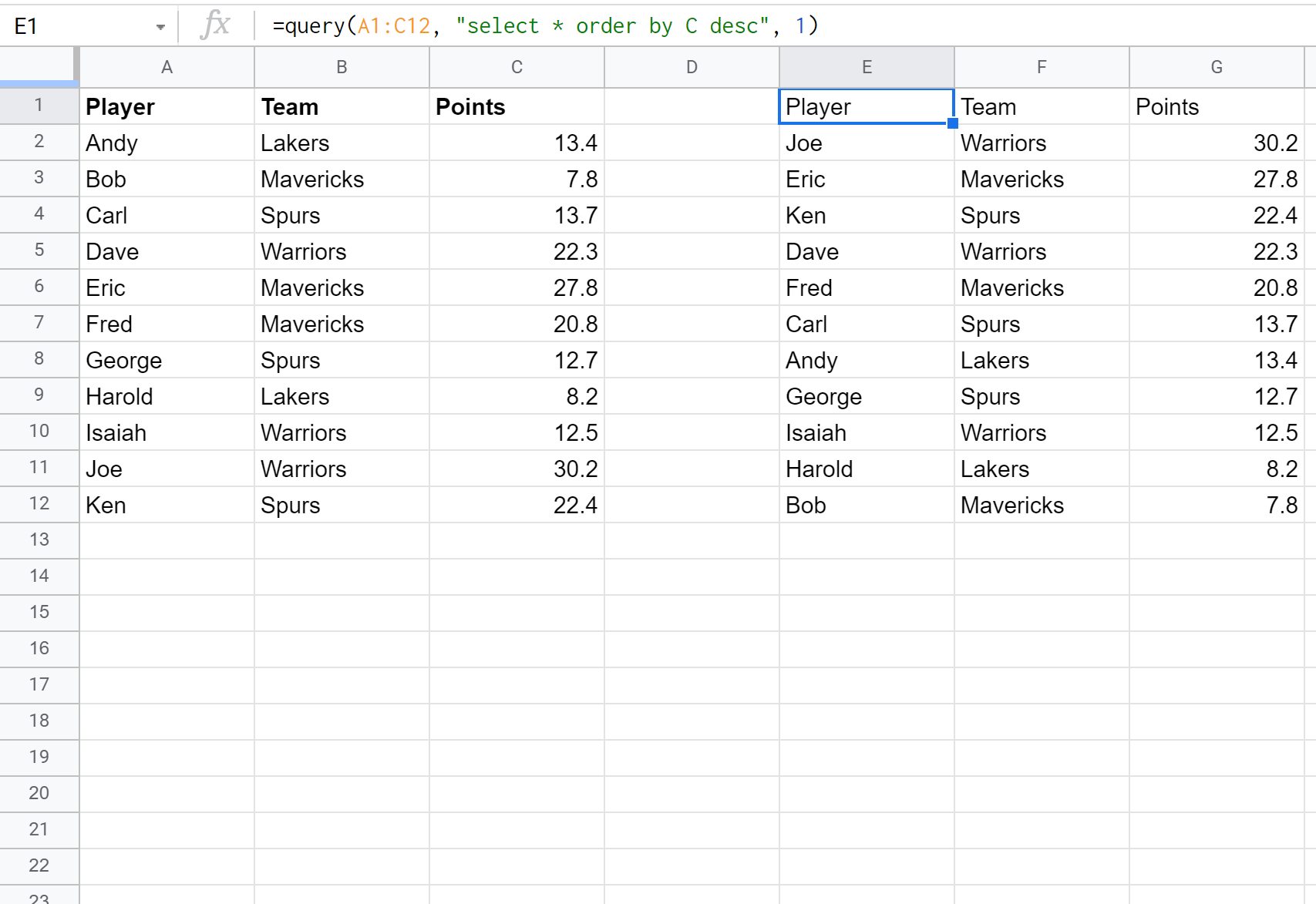
Пример 3: Порядок по нескольким столбцам
Мы можем использовать следующую формулу, чтобы выбрать все столбцы и упорядочить результаты сначала по возрастанию команды, а затем по убыванию очков:
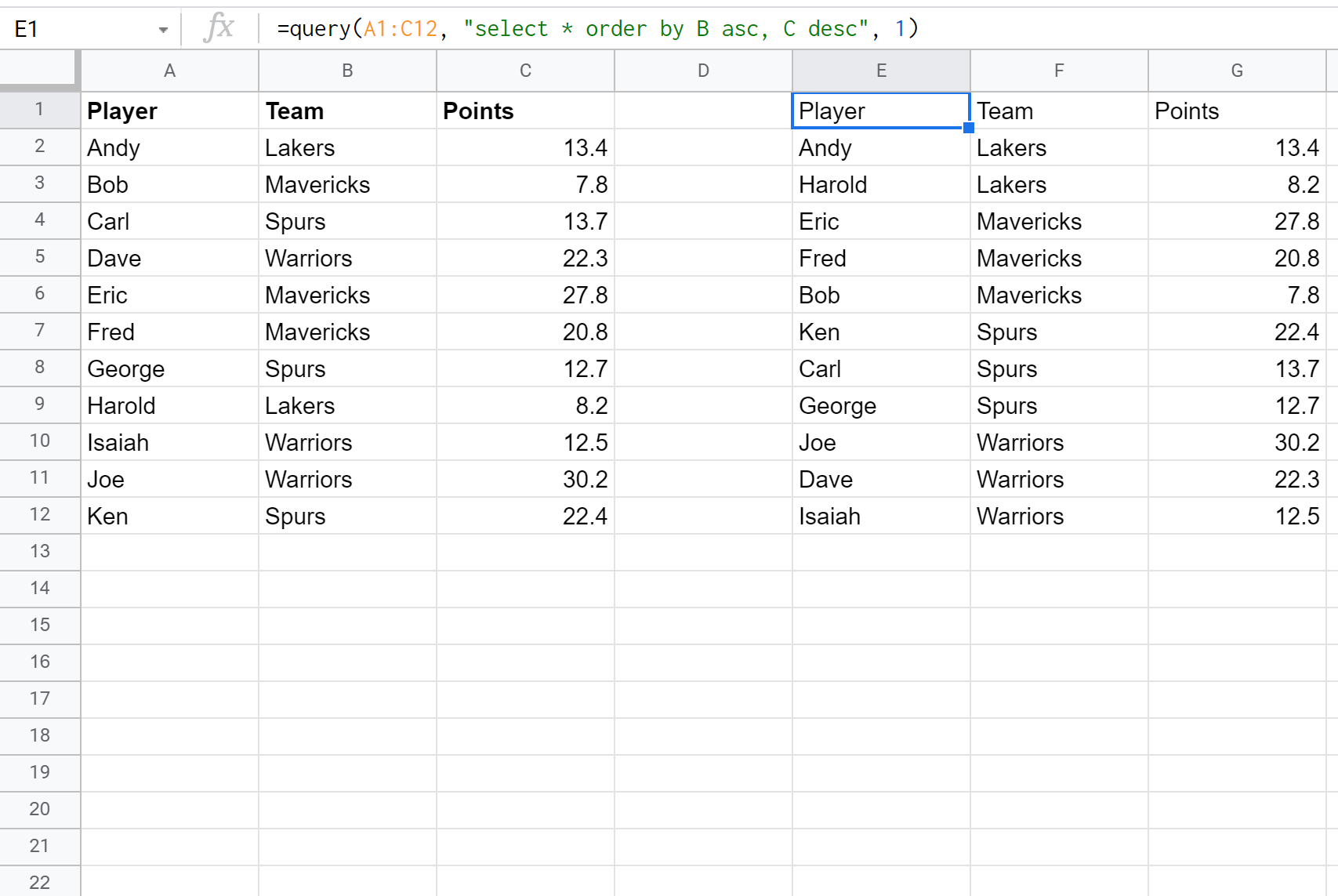
Источник: https://www.codecamp.ru/blog/google-sheets-query-order-by/
Страницы
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- …
- следующая ›
- последняя »